Introduction to SPSS
This page of the module covers a few extra tips and tricks that you may find helpful when analysing data in SPSS.
In brief, it covers the following:
- Selecting and deselecting subsets of the data
- Performing additional data transformations
- Analysing multiple response data
- Using SPSS syntax to write and run commands instead of the menus and dialogue boxes
Note that the examples covered here make use of the Household energy consumption data.sav file, which contains fictitious data for 80 people based on a short ‘Household energy consumption’ questionnaire. If you want to work through the examples provided you can download the data file using the following link:
If you would like to read the sample questionnaire for which the data relates, you can do so using this link:
Before commencing the analysis, note that the default is for dialog boxes in SPSS to display any variable labels, rather than variable names. You may find this helpful, but if you would prefer to view the variable names instead then from the menu choose:
- Edit
- Options…
- Change the Variable Lists option to Display names
Using subsets of the data
While the default in SPSS is for all of the cases in the data file to be processed every time, this doesn’t mean you need to have separate data files for each little subset of cases in order to process them separately. Instead, you can use a filter to select and process particular subsets of your data file as required.
As an example, suppose that for reporting purposes there is a need to analyse just the female responses - temporarily ignoring the other data. To select this subset of data, choose the following from the SPSS menu (either from the Data Editor or Output window):
- Data
- Select cases…
Then to select cases according to certain criteria (e.g. if they are female):
- Select If condition is satisfied
- Click If…
The expression that defines the required condition in this case is that the ‘q2’ variable (the gender variable) is equal to the value 2 (the code representing female). To define this:
- move the ‘q2’ variable into the box and add in the = 2
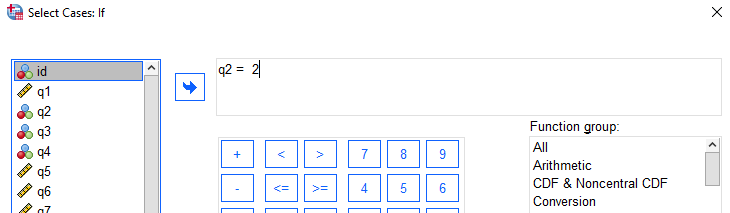
Next:
- Click on Continue
- Click on OK
In the Data View of the Data Editor window the cases that do not satisfy the selection criteria (i.e. those of other genders) will now not be visible, as they have been temporarily filtered out (or the row numbers will have a line through them, depending on the version of the software). Any analyses now will only report on the selected cases – the females.
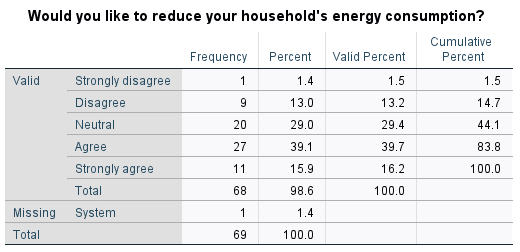
For example, to find out how many females are in each of the different categories for the ‘q8’ variable (which relates to consumption reduction), run the Frequencies procedure (as described in the Descriptive statistics page of this module) on the available data. Note that the number of cases reported in the output should be 69, the number of females, and not the 80 that constitutes the full data file.
When all of the analysis of the female only data has been completed, another subset can be isolated by going through the Select Cases process again if required. Alternatively, to revert back to the whole data file don’t forget to turn the selection/filter off! To do this, choose the following from the SPSS menu (either from the Data Editor or Output window):
- Data
- Select cases…
- select All cases
- click on OK
All 80 cases are available for processing again once the selection has been turned off.
More data transformations
While the most common types of data transformations are explained in the Transformations page of this module, this section looks at two additional, specific examples.
Converting a string variable to a numeric variable
Although SPSS does allow alphabetic/string information to be entered as part of the data file, the more in-depth statistical analysis procedures require numeric data only (even if those numbers are simply codes or values representing categories).
At the questionnaire design stage it may be very difficult to anticipate the responses that will be given though, so creating a tick-box type question can be too complicated or restrictive. Hence allowing open-ended responses may be preferable instead, and the choice then is to either numerically code the data before keying it in, or to recode the responses once they have been entered into SPSS. This section details how to do the latter using the Automatic Recode and Recode into Different/Same Variable procedures, and uses the ‘q13’ variable in the sample data file as an example. This variable stores participant responses to the question:
What kind of hot water system do you use at your property?
The variable is defined as String under Variable View, and is a nominal variable. A frequency table of the responses is as follows:
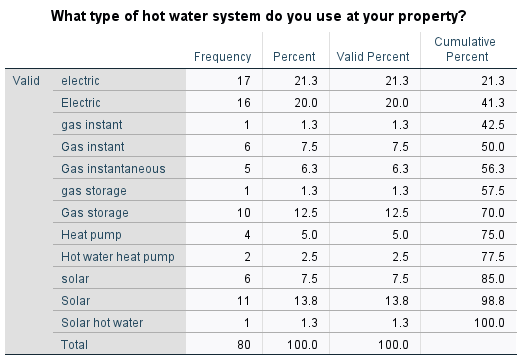
This output shows only five different types of hot water systems, but because of different spelling and terminology and different use of upper and lower case characters, twelve different responses are listed. To reduce this twelve down to the real five, the different categories need to be combined (i.e. recoded).
To complete the first part of this two-step process, from the menus choose:
- Transform
- Automatic Recode…
Now in the dialogue box that opens:
- move the variable (‘q13’) into the Variables box
- enter a name for the new variable in the New Name box (for example ‘q13_autorecode’)
- click on Add New Name
- select Treat blank string variables as user-missing (so that no category is created for these)
- select OK
The resultant output should be as follows:
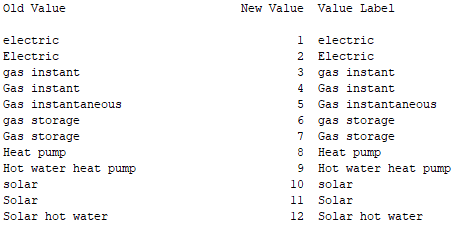
Note that the original responses have been sorted into alphabetical order and assigned a value from 1 to 12. The original data has been used to create the Value Labels for those values and all this has been put into a new variable at the end of the data file called ‘q13_autorecode’.
The second step of the process is then to reduce these 12 categories to the 5 required ones, using the standard Recode into Different Variables command (or you could use the Recode into Same Variables command in this instance if preferred). Instructions on how to do this are provided in the Transformations page of this module. In this case, the existing and new categories could be as follows:
| Existing category | New category |
|---|---|
| 1 (electric) | 1 (Electric) |
| 2 (electric) | 1 (Electric) |
| 3 (gas instant) | 2 (Instantaneous gas) |
| 4 (Gas instant) | 2 (Instantaneous gas) |
| 5 (Gas instantaneous) | 2 (Instantaneous gas) |
| 6 (gas storage) | 3 (Gas storage) |
| 7 (Gas storage) | 3 (Gas storage) |
| 8 (Heat pump) | 4 (Heat pump) |
| 9 (Hot water heat pump) | 4 (Heat pump) |
| 10 (solar) | 5 (Solar) |
| 11 (Solar) | 5 (Solar) |
| 12 (Solar hot water) | 5 (Solar) |
Computing a new variable by adding or averaging existing variables
Part of the aim of the energy consumption questionnaire is to determine how satisfied the participants are with their electricity provider. Rather than asking this as a single question though, the information is collected through four questions relating to different aspects of the service. As these questions all use the same rating system (measured on a scale of 1 to 5, with 1 indicating ‘Very unsatisfied’ and 5 indicating ‘Very satisfied’), the four variables representing these questions (‘q9’ through to ‘q12’) can be combined to come up with an overall satisfaction score.
One way of doing this is by adding all the variables together to create a score out of 20, which can be done using the Compute variable procedure as described in the Transformations page of this module. This time, you could enter the new variable name Overall_satisfaction and the numeric expression q9+q10+q11+q12:
![]()
After clicking OK , the new variable should appear at the end of the data file.
If you run the Frequencies procedure on this new variable (as described in the Descriptive statistics page of this module) you will see that there are only 78 satisfaction scores, whereas there are 80 cases in the data file. Looking at the actual data reveals why; the data in row 30 is missing for all four of the variables ‘q9’ to ‘q12’, and the data in row 31 is missing for variables ‘q10’ and ‘q12’. Since the numeric expression shown above only calculates new values for those cases that have complete data, the new variable has not been computed for rows 30 and 31.
Sometimes this will be what you want, but other times you will require data for the new variable regardless of whether some of the data is missing or not (note that if there is missing data for all the variables, there will automatically be missing data for the new variable). To do this simply requires that a different numeric expression is used within the Compute variable procedure, which makes use of the sum function.
For example, you could alter the numeric expression for the variable you have just created to sum(q9 to q12) (note that the word ‘to’ can be used between the variables in this case as they occur one after the other in the data file; if this isn’t the case, you would need to list the variable names separated by commas instead):
![]()
With this new numeric expression, there is now a value for the ‘Overall_satisfaction’ variable in row 31.
You may also like to experiment with other formulas. For example, if you wanted to calculate an average overall satisfaction score instead you could also try using two different, similar numeric expressions:
- The numeric expression (q9 + q10+ q11 + q12)/4 will again have missing data for both rows 30 and 31.
- The numeric expression mean(q9 to q12) (or mean(q9, q10, q11, q12) if the variables are not in order) will have missing data only for row 30. For row 31, the average will be calculated by dividing by 2 instead of 4, since there are only two variables with data.
Regardless of which formula you choose to use, the new variable can then be analysed in the usual way.
Multiple response data
The sample questionnaire provided contains two questions with multiple parts: question 15, which asks whether the participant owns any heating or cooling products and prompts them to list up to three if so; and question 16, which asks the participant whether or not they own five different items.
While the data for each part of these questions is required to be stored in a separate variable (for example ‘q15’, ‘q15.1’, ‘q15.2’ and ‘q15.3’; and ‘q16.1’, ‘q16.2’, ‘q16.3’, ‘q16.4’ and ‘q16.5’), often the data needs to be analysed together in sets. These are known as multiple response sets in SPSS, and this section explains how to create, analyse and display them.
Creating and using multiple response sets
There are two ways of creating multiple response sets in SPSS. One of the ways (the Multiple Response option in the Analyze menu) does not retain the sets between SPSS sessions. The other does as long as the data file is saved again once they have been created; it is this latter way that is used in this example. There are two ways to access this method using the menu options in SPSS, the first of which is by selecting:
- Data
- Define Multiple Response Sets…
The second way is by selecting:
- Analyze
- Tables
- Multiple Response Sets…
Either way, you can then create sets in the Define Multiple Response Sets window. For example, to create a set containing the ‘q15.1’, ‘q15.2’ and ‘q15.3’ variables (in order to analyse all of the specified heating and cooling methods together) do the following:
- move the three variables containing the heating and cooling methods (‘q15.1’, ‘q15.2’, and ‘q15.3’) into the Variables in Set panel
- click on Categories (because the responses were coded into different categories)
- give the set a Name (for example ‘q15methods’)
- give the set a Label (for example ‘Heating and cooling methods’)
- click on Add
The set for question 16 can be created at the same time, but this time the variables are dichotomous and the answers of interest are the ‘Yes’ ones (coded 1). You can create this set as follows:
- move the five variables relating to question 16 into the Variables in Set panel
- click on Dichotomies
- enter the counted value as 1
- give the set a Name (for example ‘q16’)
- give the set a Label (for example ‘Items owned’)
- click on Add
Both sets will now be listed in the Multiple Response Sets panel, so now:
- Click on OK
Once you have created the multiple response sets some output will appear in the results window (not shown here) detailing the variables used. The two sets will not be visible in the data file, except as the separate variables making up the sets, but they are set up for use in any of the Tables procedures. The sets will be retained for this use if the data file is saved before ending the SPSS session.
To use these sets in Custom Tables, from the menus choose:
- Analyze
- Tables
- Custom Tables
- click on OK
The Custom Tables dialogue box is arranged differently to most other procedures in that it has a ‘Canvas’ area where specifications are dragged and dropped to build the required table. The concept is similar to using the Chart Builder for producing graphs.
The multiple response sets that have been defined will be listed after the variables in the panel on the left hand side. The icon with four squares depicts a set with categorical variables while the one with two squares is for a dichotomous set.
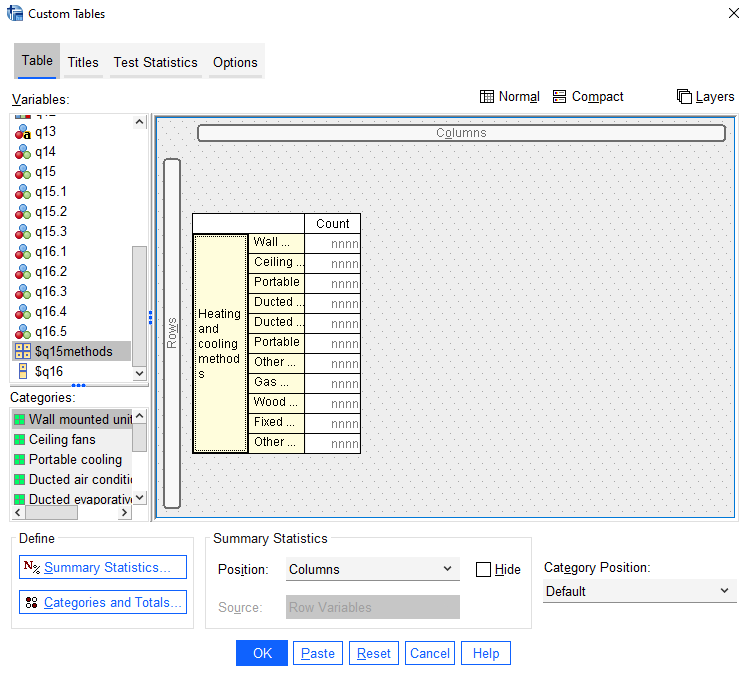
To create a frequencies table for the ‘q15methods’ set:
- click on ‘q15methods’
- drag and drop it into the Rows panel
A mock up of the table will appear in the canvas, which should look like the following (note there are no percentages or totals provided automatically, but you can add these as detailed below):
To include percentages on the table:
- click on Summary Statistics…
- click on the plus sign next to Column Percent
- select Column N %
- use the arrow head to move it into the Display box
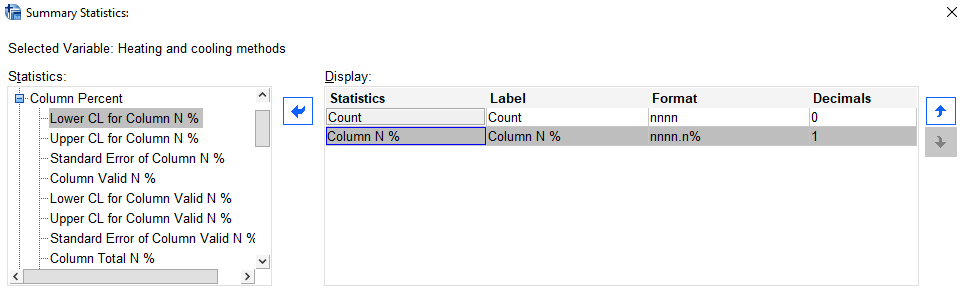
- click on Apply to selection
- click on Close
To include a total on the table:
- click on Category and Totals…
- select Total in the Show box on the right hand side
- click on Apply
The canvas will now show the table with percentages and a total included.
- click on OK
The resultant table should look like this:
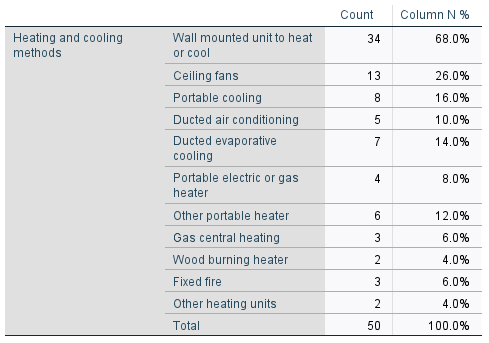
Note that the percentages are automatically based on the number of valid cases, i.e. those people who answered the question by listing at least one heating or cooling method.
The tables for dichotomous multiple response sets are created in exactly the same way.
To create a two-dimensional table, similar to a Crosstabs table, the second variable will need to be dragged and dropped into the Columns panel. Row or column percentages can then be chosen as required.
Graphing multiple response data
Once multiple response sets have been defined they can be used to create graphs in the Chart Builder, in the same way as for variables.
To create a Bar chart of the multiple response set ‘q15methods’, for example, from the menus choose:
- Graphs
- Chart Builder
- click on OK to say the all variables have been defined appropriately (if required)
- drag the simple bar chart image onto the canvas
- drag the ‘q15methods’ set and drop it on the X axis
By default, the Y axis will display the count for each category. To change this to response percentages (i.e. the percentage of respondents who selected each category) make the following change in the Element Properties dialogue box:
- choose Response Percentage from the drop down list in the Statistics area
- click on OK
The resultant chart should look something like the following:
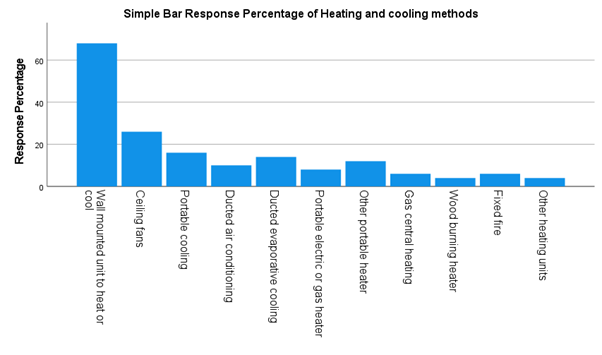
It can be edited using the Chart Editor, as detailed in the Charts page of this module.
Using SPSS syntax
SPSS syntax is a command language that is unique to SPSS. Rather than using the SPSS menus and dialogue boxes to perform procedures, as per the examples in this module, a syntax file can be used to write and then run commands. While this may seem a daunting prospect if you are not familiar with command languages, note that you do not have to write your own commands from scratch in order to create a syntax file unless you want to. In fact, you can create commands in a syntax file by doing any of the following:
- pasting commands that you have built up using the menus and dialogue boxes
- copying and pasting commands that are displayed in your output file
- creating your own commands from scratch by typing them directly into the syntax file
- editing commands that you have already pasted in order to create new commands
- a combination of any or all of the above.
There are many benefits to using a syntax file, some of which are that it:
- provides a record of all the procedures you have performed
- means you have a set of commands that can be repeated regularly, such as for monthly reports
- allows you to build a set of instructions that can be used to test different portions of data as it arrives
- is generally quicker, in particular when performing a large number of procedures.
This section details a few of the different ways you can create and run commands in a syntax file.
Rules for syntax
Before we look at some of the ways to create commands in a syntax file, note that there are a few basic rules and guidelines to follow when creating or editing syntax. These are as follows:
- Every new command should start on a new line.
- It is best to start the first word of a new command on the far left hand side of the line in order. If the command contains subsequent lines, these should be indented at least one space (tab can be used to make the first line of each command really stand out).
- The commands are not case sensitive, so you can use upper or lower case or a mixture of both.
- Generally the commands can be abbreviated to the first four letters as long as they are unique to that command. Variable names cannot be abbreviated though.
- Commas or spaces can generally be used to separate names of variables in a list, or the word ‘to’ can be used if the variables occur one after the other in the data file.
- The end of each command must be signalled by a full stop.
- You can leave blank lines between commands to aid readability, but must not embed a blank line within a command.
- You can include comments by starting a line with at least one asterisk (*) and finishing with a full stop.
Creating a syntax file
A few different ways to add commands to a syntax file are detailed below. Click on the relevant heading to learn more about it:
You can paste commands into a syntax file from an SPSS dialogue box rather than actually running the procedure. For example, to paste the command for creating a frequency table for the ‘q2’ variable into a syntax file, choose the following from the SPSS menu:
- Analyze
- Descriptive Statistics
- Frequencies…
- Click on the ‘q2’ variable
- Click on the arrow head to move it to the right hand box
- Click on Paste.
The procedure will not be executed, and instead a new syntax file will open which contains the relevant command. It should look like the following:
FREQUENCIES VARIABLES=q2
/ORDER=ANALYSIS.
(Note that the syntax file may also start with a command stating which data set is being used. For example, ‘DATASET ACTIVATE DataSet1’. This is not required if you only have one data set open, but if you have more than one you will need to ensure that this command is included and that it refers to the correct data set.)
The first line of the ‘FREQUENCIES’ command tells SPSS that we want to obtain frequencies for the variable ‘q2’. The second line relates to a default setting of this command, and these are often included when you paste from a dialogue box (typically they relate to handling of missing data or the choices under the ‘options’ button). As a general rule of thumb, if you didn’t have to click on something to get it you don’t need to specify it in the syntax file because it is the default anyway, which is the case here. Hence we can remove this line from the command, as long as we put a full stop at the end of the first line instead. The command now becomes:
FREQUENCIES VARIABLES=q1.
Once this or any other command is in the syntax window it can be edited or copied, pasted and edited as required. For example, you could copy and paste the command then edit it to request frequency tables for variables ‘q14’ and ‘q15’ at the same time, as follows:
FREQUENCIES VARIABLES=q14 q15.
Syntax commands can be included as part of your output file when you perform procedures, in which case you can simply copy and paste them into a syntax file. If the commands are not included in your output file already, you can request this by selecting the following from the SPSS menu:
- Edit
- Options…
- click on the Viewer tab
- select Display commands in the log
- click on OK
All the commands that you run, either from the syntax or through dialogue boxes, will now be listed as part of your output file. This can be an easy way of learning what the syntax commands look like and it can be a great way of trying something, examining the output, and only creating the syntax when you have achieved exactly the desired result.
As an example, run an independent samples (t) test to see if there is a significant difference in the mean summer daily energy consumption between those who do and don’t own a swimming pool. You can do this by choosing the following from the SPSS menu (refer to the Inferential statistics page of this module for more information on this test):
- Analyze
- Compare means
- Independent-Samples T-Test
- make the Test variable q7
- move the continuous variable (‘q6’) into the Test Variable(s) box
- move the categorical variable (‘q16.4’) into the Grouping Variable box
- click on Define Groups…
- keep Group 1 as category 1 and Group 2 as category 2 and select Continue
- click on OK
The resultant syntax output in the output file (above the tables) should look something like:
T-TEST GROUPS=q16.4(1 2)
/MISSING=ANALYSIS
/VARIABLES=q6
/ES DISPLAY(TRUE)
/CRITERIA=CI(.95).
You can then copy and paste this command into an existing or new syntax file (to create a new one for this purpose if required, go to the File menu and choose New and then Syntax). Either way, once you have a syntax file open you can transfer the command to it as follows:
- double click on the piece of syntax to select it
- highlight and copy the command (CTRL+C or right click and select Copy)
- navigate to the relevant syntax file
- paste the command on a new line in the syntax file (CTRL+V or right click and select Paste)
The new command can then be copied and edited in the same way as any other command. In particular, note that the command may include default settings (typically relating to handling of missing data or the choices under the ‘options’ button). As a general rule of thumb, if you didn’t have to click on something to get it you don’t need to specify it in the syntax file because it is the default anyway, and these lines can be removed. For example, the following lines can be removed from this particular command:
/MISSING=ANALYSIS
/ES DISPLAY(TRUE)
/CRITERIA=CI(.95).
Just make sure, as always, that you put a full stop at the end of the edited command. In this case the new command should be as follows:
T-TEST GROUPS=q16.4(1 2)
/VARIABLES=q6.
You can create a new syntax file, choose the following from the SPSS menu:
- File
- New
- Syntax
You can now write your own commands in the syntax file according to the rules and suggestions detailed previously. Note that if you know what command to use but are not sure of the exact format required, you can type the command name then click on the Syntax Help icon at the top of the syntax window:

Information about that command will then be provided to you in the online documentation, which will hopefully allow you to proceed with creating the command.
As an example, you could write a syntax command to compute a new variable called ‘Overall_satisfaction’ by using the sum function on the four variables q9 to q12 (as in the More data transformations section of this page). This command would be as follows (note that the word ‘to’ can be used between the variables in this case as they occur one after the other in the data file; if this isn’t the case, you would need to list the variable names separated by commas instead):
compute Overall_satisfaction = sum(q9 to q12).
You could also add an additional command to create a label for this variable, as follows:
variable labels Overall_satisfaction Overall satisfaction with electricity provider.
You could then create a command to display the descriptive statistics for this variable, as follows:
descriptives variables = Overall_satisfaction.
Next, you could recode the ‘Overall_satisfaction’ variable into a new categorical variable called ‘Satisfaction_grouped’. This variable could have two categories based on the mean ‘Overall_satisfaction’ value of 15.04; one category could consist of people with ‘Overall_satisfaction’ values below the mean, and the other could consist of people with ‘Overall_satisfaction’ values above the mean. The required commands to do this, as well as to create labels for the variable and for the categories, are as follows (note the use of the syntax ‘lo’, ‘thru’ and ‘hi’ when creating the categories):
recode Overall_satisfaction (lo thru 15.04 = 1)(15.04 thru hi=2) into Satisfaction_grouped.
variable labels Satisfaction_grouped Overall satisfaction with electricity provider (grouped).
value labels Satisfaction_grouped 1 ‘Below the mean’ 2 ‘Above the mean’.
Finally, you could create a crosstabulation for the ‘q3’ variable and the new ‘Satisfaction_grouped’ variable, with row and column percentages and the Chi-square statistic, in order to test whether there is any association between having children and the satisfaction grouping. The command to do this is as follows:
crosstabs tables= q3 by Satisfaction_grouped
/cells = count row col
/statistics=chisq.
Running syntax commands
Once you have added a command or commands to your syntax file you will need to run them in order to have the procedures performed. You can do this using the ‘Run’ menu in the syntax file, or by pressing the Run Selection icon (a green triangle). The options in the ‘Run’ menu are as follows:
- All - this runs all the commands that are in the current open syntax window.
- Selection - this runs only the command(s) that have been highlighted in the syntax window, or the command where the cursor currently is.
- To End - this runs the commands from where the cursor currently is to the end of the syntax file.
- Step Through - this runs the commands one at a time starting from the first command in the syntax window (Step Through From Start) or from where the cursor currently is (Step Through From Current). After a given command has run the cursor advances to the next command and you can continue the step through process by selecting Continue.
Note that pressing the Run Selection icon is equivalent to choosing Selection from the menu.
You might notice that if you only run a command to compute or recode a new variable, SPSS won’t actually produce the output in your data file until it is actually needed (e.g. until you use it in a statistical procedure). Until this time, the message ‘Transformations pending’ will appear along the bottom of the various SPSS windows.
To make the transformation actually happen, you can do any of the following:
- go to the Transform menu and click on Run pending transformation
- run a procedure that uses the new variable, such as the descriptives procedure
- include the command execute after the command for computing or recoding the variable, then run both.
Further Resources
Congratulations on making it to the end of the module! We hope you found it a useful introduction to SPSS. If you are interested in learning more about it, and in particular finding out how to conduct other statistical tests, you may like to make use of the following textbook:
Allen, P., Bennett, K., & Heritage, B. (2014). SPSS Statistics version 22: A practical guide. (3 ed.) Sydney: Cengage Learning Australia Pty Limited.